
解析robot.txt的作用、用途及编写方法
在浩瀚的网络世界中,信息的获取与传播依赖于无数网页的相互链接与交互。然而,在这庞大的信息网络中,如何确保网站内容的合理使用与访问,同时保护网站拥有者的权益,便成为了一个重要议题。此时,“robots.txt”文件应运而生,它作为网站与搜索引擎等网络爬虫之间的“交通规则”,扮演着至关重要的角色。本文将围绕“robot.txt是做什么的?有什么用处?如何编写?”这三个关键词,深入探讨robots.txt的奥秘。
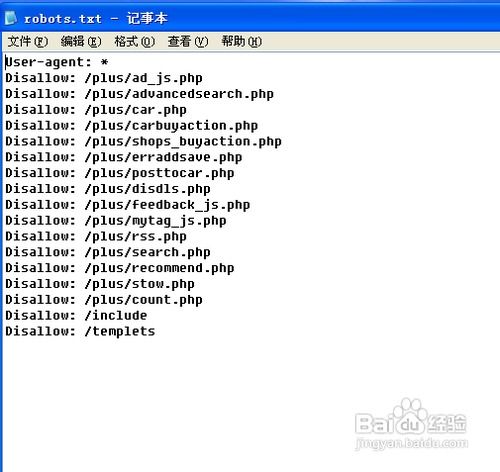
robot.txt是做什么的?
简单来说,robots.txt是一个放置在网站根目录下的纯文本文件,其作用是指导搜索引擎爬虫(即网络机器人)哪些页面可以访问,哪些页面需要避免访问。这个机制基于一种被称为“robots exclusion standard”(机器人排除标准)的协议,它允许网站管理员通过预定义的规则,对搜索引擎爬虫的行为进行一定程度的控制。

robots.txt文件的存在,既是对搜索引擎的一种尊重,也是对网站内容保护的一种手段。通过明确哪些内容可以被索引,哪些内容应当被排除,网站管理员可以更好地管理自己的网站信息,避免不必要的曝光或敏感信息的泄露。

有什么用处?
1. 保护隐私与安全:对于包含个人隐私、商业秘密或敏感数据的网页,通过robots.txt文件可以禁止搜索引擎爬虫访问,从而减少信息泄露的风险。
2. 优化搜索排名:通过精确控制搜索引擎爬虫的访问范围,网站管理员可以引导爬虫优先访问并索引重要页面,提高这些页面在搜索结果中的排名,从而增强网站的可见性和吸引力。
3. 减轻服务器负担:对于更新频繁或资源消耗大的页面,通过限制搜索引擎爬虫的访问频率,可以有效减轻服务器的负担,提高网站的稳定性和响应速度。
4. 防止内容抄袭:虽然robots.txt不能直接防止内容被复制,但它可以阻止搜索引擎索引某些特定页面,从而在一定程度上减少内容被抄袭后通过搜索引擎广泛传播的可能性。
5. 测试页面管理:在网站开发或更新过程中,经常会有测试页面或未完成的页面。通过robots.txt文件,可以暂时阻止这些页面被搜索引擎索引,避免给用户带来困惑或不良体验。
如何编写?
编写一个有效的robots.txt文件,需要遵循一定的格式和规则。下面是一个基本的robots.txt文件示例,以及相应的解释:
```plaintext
User-agent:
Disallow: /private/
Disallow: /tmp/
Disallow: /cgi-bin/
User-agent: Googlebot
Allow: /
Disallow: /noindex/
User-agent: Slurp
Disallow: /
```
1. User-agent行:指定这条规则适用于哪个搜索引擎爬虫。`*`代表所有爬虫,而特定的爬虫名称(如Googlebot、Slurp等)则指针对特定爬虫的规则。
2. Disallow行:告诉搜索引擎爬虫不要访问哪些路径下的页面。路径可以是具体的文件夹(如`/private/`),也可以是具体的文件(虽然在实际使用中较少)。
3. Allow行(可选):与Disallow相反,Allow行用于指定爬虫可以访问的路径。需要注意的是,Allow和Disallow的规则是相对的,且遵循“最具体优先”的原则。例如,如果某条规则先指定了`Disallow: /`(禁止访问所有页面),随后又指定了`Allow: /public/`(允许访问/public/路径下的页面),则只有/public/路径下的页面可以被访问。
4. 顺序与优先级:在编写robots.txt文件时,规则的顺序和优先级至关重要。通常,较具体的规则(即路径更具体)会覆盖较不具体的规则。此外,对于同一User-agent,后出现的规则会覆盖先出现的规则。
5. 注释与空白:robots.txt文件支持注释(以``开头的行)和空白行(仅包含空格或制表符的行),这些行不会被搜索引擎爬虫解析为规则,但可以增加文件的可读性。
6. 测试与验证:编写完成后,务必使用各种搜索引擎提供的robots.txt测试工具来验证文件的正确性。这些工具可以帮助你发现潜在的语法错误或逻辑问题,确保robots.txt文件能够按照预期工作。
7. 更新与维护:随着网站内容的不断更新和变化,robots.txt文件也需要定期更新和维护。这包括添加新的Disallow规则以保护新生成的敏感内容,以及删除不再适用的规则以优化搜索引擎的访问效率。
综上所述,robots.txt文件是网站管理中不可或缺的一部分,它不仅能够保护网站的隐私与安全,还能优化搜索排名、减轻服务器负担、防止内容抄袭以及管理测试页面。通过遵循一定的格式和规则编写robots.txt文件,并定期进行测试与维护,网站管理员可以更好地控制搜索引擎爬虫的行为,为网站创造一个更加健康、有序的信息环境。
- 上一篇: 打造梦幻墙面:自制神奇相框秘籍
- 下一篇: 超级无敌流浪汉4:畅享无敌版冒险小游戏






-
 揭秘:XX的用途与使用方法,Q卡全解析及实操指南资讯攻略12-02
揭秘:XX的用途与使用方法,Q卡全解析及实操指南资讯攻略12-02 -
 深入解析:innerHTML与innerText的区别与用途资讯攻略11-07
深入解析:innerHTML与innerText的区别与用途资讯攻略11-07 -
 揭秘!95543电话号码归属及用途资讯攻略11-30
揭秘!95543电话号码归属及用途资讯攻略11-30 -
 GSP上岗证书定义及用途资讯攻略11-12
GSP上岗证书定义及用途资讯攻略11-12 -
 隔夜茶的安全性及创意用途全解析资讯攻略11-23
隔夜茶的安全性及创意用途全解析资讯攻略11-23 -
 凤仙花有哪些功效或用途?资讯攻略11-18
凤仙花有哪些功效或用途?资讯攻略11-18





