
深入理解Robots协议
robots协议详解

在互联网的世界中,robots协议(robots.txt)扮演着至关重要的角色。这一协议不仅关乎网站的搜索引擎优化(SEO),还涉及到用户隐私和网站安全的保护。robots协议是一个约定俗成的道德规范,它通过特定的文件(robots.txt)指导搜索引擎爬虫(俗称“搜索蜘蛛”)哪些页面可以抓取,哪些页面不能抓取。本文将从robots协议的定义、原则、功能、文件写法及实际应用等多个方面对其进行详细介绍。

一、robots协议的定义
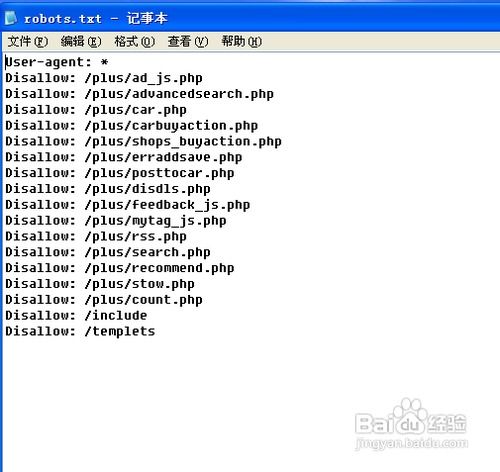
robots协议,也称爬虫协议、爬虫规则,是网站与搜索引擎之间的一种通信机制。通过建立一个名为robots.txt的文件,网站可以明确告知搜索引擎哪些页面是允许被抓取的,哪些页面是不允许被抓取的。这个文件通常位于网站的根目录下,是搜索引擎爬虫访问网站时要查看的第一个文件。
二、robots协议的原则
robots协议是基于以下原则建立的:
1. 搜索技术应服务于人类:同时尊重信息提供者的意愿,并维护其隐私权。
2. 网站有义务保护其使用者的个人信息和隐私不被侵犯。
这些原则确保了搜索引擎在提供高效服务的同时,不会侵犯网站的隐私权和用户的信息安全。
三、robots协议的功能
robots协议的功能主要包括以下几个方面:
1. 控制搜索引擎爬虫的爬取范围:防止搜索引擎抓取网站中的敏感信息或垃圾信息。
2. 提高网站的搜索引擎收录效率:避免搜索引擎爬虫抓取大量无用的页面,从而提升网站的搜索引擎排名。
3. 屏蔽网站中的大文件:如图片、音乐、视频等,以节省服务器带宽。
4. 屏蔽死链接:方便搜索引擎更有效地抓取网站内容。
5. 设置网站地图链接:引导搜索引擎爬虫爬取页面。
四、robots.txt文件的写法
robots.txt文件是一个纯文本文件,其语法相对简单,主要包括以下指令:
1. User-agent:指定指令适用的搜索引擎爬虫。使用“*”表示所有搜索引擎爬虫。
2. Disallow:禁止搜索引擎抓取的路径。可以指定绝对路径或相对路径。
3. Allow:与Disallow相反,指示搜索引擎允许抓取的页面路径。
4. Crawl-delay:指定爬取间隔时间(单位为秒),用于控制爬虫访问网站的速度,避免对服务器造成过大的负载。需要注意的是,并非所有搜索引擎爬虫都支持此指令。
五、robots.txt文件的示例
以下是一些robots.txt文件的示例,以帮助理解其具体应用:
示例1:禁止所有搜索引擎访问网站的任何部分
```
User-agent:
Disallow: /
```
示例2:允许所有的搜索引擎爬虫访问(或者也可以建一个空文件“/robots.txt”)
```
User-agent:
Allow: /
```
示例3:禁止某个搜索引擎的访问
```
User-agent: BadBot
Disallow: /
```
示例4:允许某个搜索引擎的访问
```
User-agent: Baiduspider
Allow: /
```
示例5:禁止搜索引擎抓取网站的所有图片和视频
```
User-agent:
Disallow: /images/
Disallow: /videos/
```
示例6:综合应用
```
User-agent:
Disallow: /private/
Disallow: /admin/
Allow: /public/
Crawl-delay: 10
```
在这个示例中,所有搜索引擎爬虫都被禁止访问/private/和/admin/目录,但允许访问/public/目录,且爬虫访问速度被限制为每10秒一次。
六、robots协议的注意事项
在编写robots.txt文件时,需要注意以下几点:
1. 文件名必须为robots.txt:且文件必须放在网站的根目录下。
2. 指令必须以英文状态下的大写字母开头:空格和分号不能省略。
3. 路径必须指向具体的页面或目录:不能使用通配符。
4. 指令的顺序无关紧要:但应保持清晰和一致,以便理解和维护。
七、robots协议的实际应用
robots协议在网站管理和SEO优化中有着广泛的应用,包括但不限于以下几个方面:
1. 屏蔽网站的后台管理系统:防止搜索引擎爬虫抓取到网站后台的敏感信息。
2. 限制搜索引擎的抓取频率:通过Crawl-delay指令控制爬虫访问速度,减轻服务器负担。
3. 优化搜索引擎收录:通过精确控制爬虫抓取范围,提高网站的搜索引擎收录效率和排名。
4. 保护用户隐私:防止搜索引擎抓取到包含用户个人信息的页面。
八、robots协议的局限性
尽管robots协议
- 上一篇: 如何删除微信聊天记录?
- 下一篇: 哪六部悬疑电影令人印象深刻?《鬼夫》中貌美如花的妻子,背后竟有…






-
 详解robots.txt文件的定义与用途资讯攻略11-27
详解robots.txt文件的定义与用途资讯攻略11-27 -
 解析robot.txt的作用、用途及编写方法资讯攻略11-27
解析robot.txt的作用、用途及编写方法资讯攻略11-27 -
 银行协议利率的定义是什么?资讯攻略12-30
银行协议利率的定义是什么?资讯攻略12-30 -
 如何理解和使用YZX USB协议测试器进行充电协议测试?资讯攻略11-04
如何理解和使用YZX USB协议测试器进行充电协议测试?资讯攻略11-04 -
 揭秘组态:深入理解组态的核心概念资讯攻略11-02
揭秘组态:深入理解组态的核心概念资讯攻略11-02 -
 揭秘SENT总线串行协议的解码艺术资讯攻略11-17
揭秘SENT总线串行协议的解码艺术资讯攻略11-17





